The Task
As almost everyone in the ML community knows by now, the transformer architecture has been pulling away from architectures like CNNs for some time, with increased ability to model long-range dependencies and better scaling laws. However, within vision, the techniques used in research to boost the default performance of ViTs (not including their own training innovations) seem to still be using the same ViT and optimizer as the original paper. The goal of this blog is to show the effect of transformer innovations that (mm)LLMs have been using for some time, or in some cases things that are still new even there. The innovations I chose to test are SwiGLU activations, removing bias terms from all layers, and swapping AdamW for the Muon optimizer. There are many vision tasks I could have tested this on, but I am particularly fond of SSL (Self-Supervised Learning), so I chose to train ViT-S/16 on an MAE task with the ImageNet-1K dataset.
Default Parameters
Encoder / Decoder
Training
Muon Parameters
Results
Pretraining
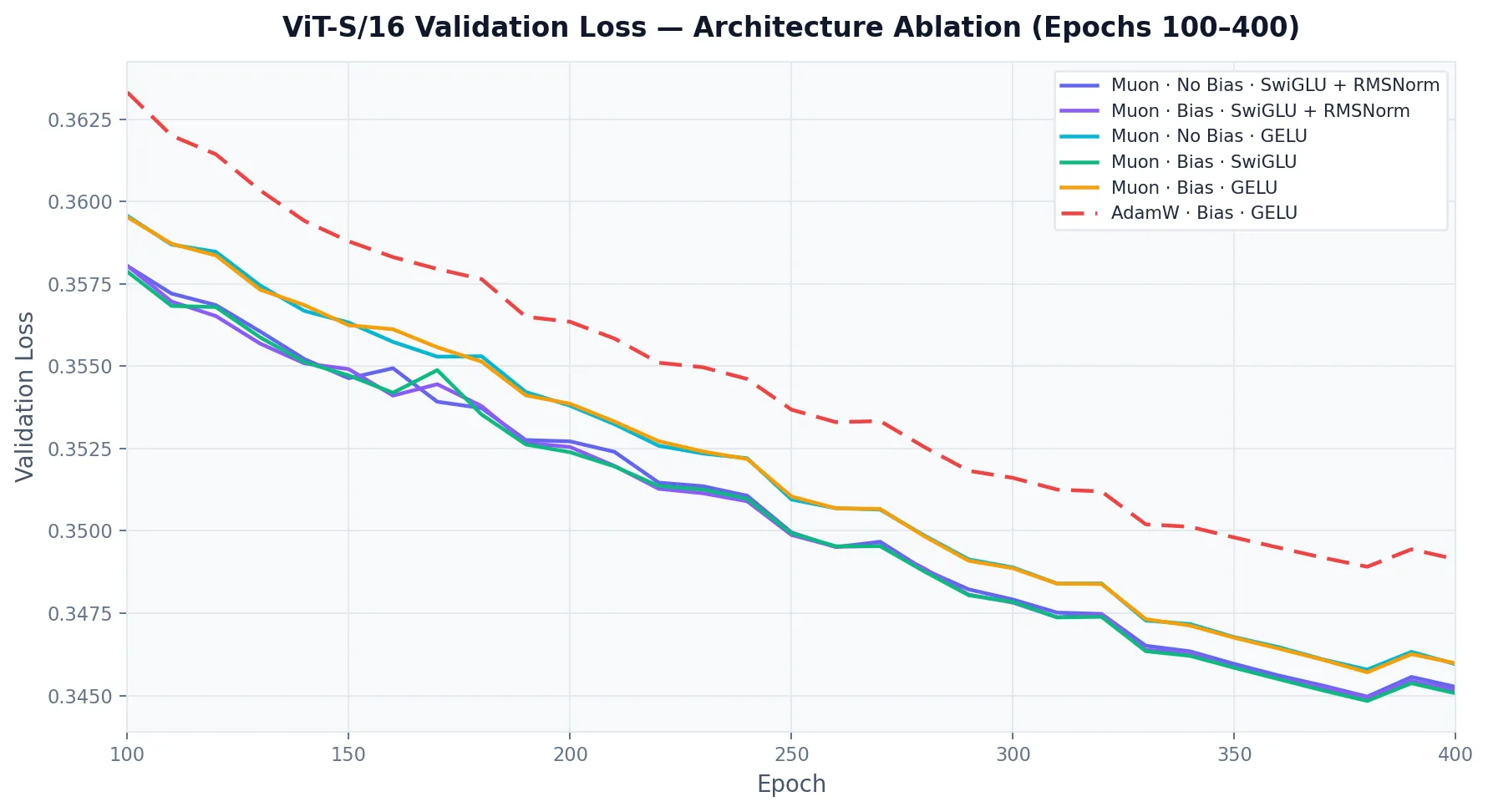
Interpreting the results, the largest change came from moving from AdamW to Muon for the 2D weight matrices1. Surprisingly, challenging a lot of history in machine learning, removing the bias has very little effect vs the Muon baseline.
This idea has been studied, models like LLaMa have actually done this for efficiency gains, noting that the shift parameter of the LayerNorm function essentially can absorb the job of the biases, and my results validate this claim for MAE ViT training. However, the next result is what really surprised me. I wanted to see if this claim was really accurate, so I ran RMSNorm + SwiGLU with and without biases. As you can see, it had once again, almost no effect. This result is not what I expected and there is no definite answer for this effect in the literature. My theory is with how deep these models are along with activation functions, there is simply no need for explicit shifts in linear layers.
Another note, which to some isn’t surprising, is replacing GELU with a SwiGLU style FFN with equivalent parameters (scale the hidden dim by ) further improved performance of the model.
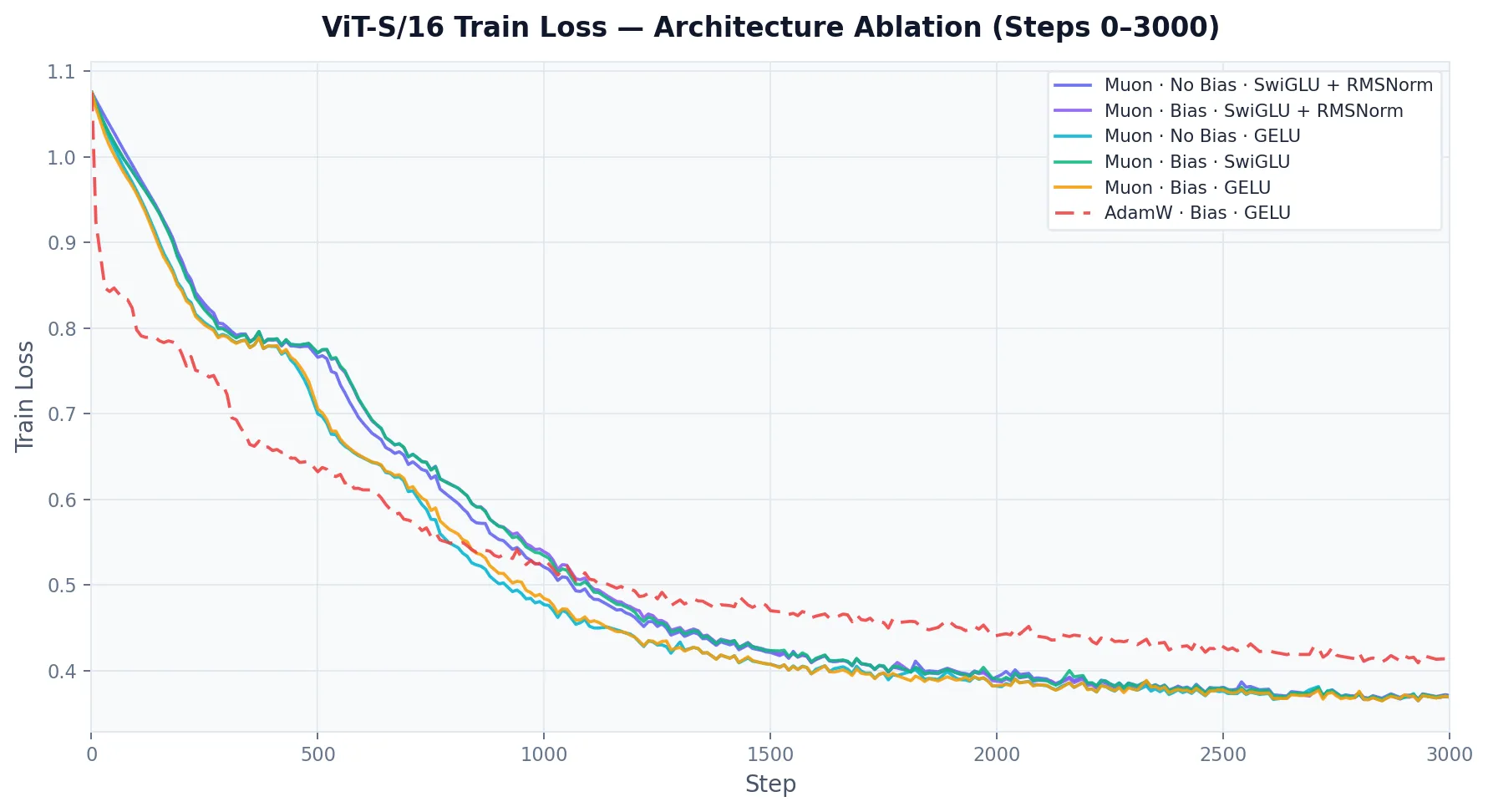
Notably, AdamW initially had faster convergence than Muon though was quicky overtaken and Muon never looked back. My theory on this is that Muon has no bias correction like AdamW:
Muon initializes its momentum with , so early on the momentum is weighted towards a zero matrix.
Attentive Probe
For those who are unfamiliar, an attentive probe is a good way to truly get a feel for how well a pretrained model
learned features, without heavy fine-tuning. A standard linear probe is simply one matrix multiplication that transforms
the model’s learned outputs into an ImageNet-1k class guess. The reason an attentive probe was used here, is because
MAE based architectures, don’t normally have a [CLS] token, which is normally what you feed into a linear probe.
Attentive probes have a MHSA layer than takes a randomly initialized query token, and attends to it with all of the
ViT patch tokens. Then that query token is fed through the linear layer to produce the output, still no activation functions
are used, making it truly a linear model on top of the learned features of the MAE.
I ran a grid sweep over learning rates and weight decays with cosine annealing over 10 epochs with a 1 epoch linear warmup. I used best pretrained model, being the SwiGLU + LayerNorm model with biases trained with the Muon optimizer.
Weight decays: 5e-4, 1e-3, 5e-2
Peak learning rates: 1e-5, 2e-5, 5e-5, 1e-4, 2e-4, 5e-4, 1e-3, 2e-3, 5e-3, 1e-2
Once again, the Muon optimizer was able to outperform AdamW. Because this run was a lot shorter and with far fewer parameters (since the MAE remains frozen), it shows that even very small models on short training runs, still benefit from using the Muon optimizer. This lends further to the general applicability of the optimizer.
Summary
My experiments tell a clear story: (mm)LLM transformer innovations are not limited to language modeling. All the performance or efficiency swaps mirror their perceived benefits in ViT. SwiGLU increased model performance without changing the parameter count. Muon provided an easy way to get better performance with no real downsides. RMSNorm proved it can perform just about as well as LayerNorm without the overhead. Lastly, the role of biases in deep neural networks might need to be re-examined, even when removing the normalization-based justification entirely, as with RMSNorm, they remain inconsequential. This feels like a genuinely open area worth further study.
Repository: https://github.com/hachoj/iSSL
Footnotes
-
Muon relies on orthogonalization via Newton-Schulz iterations, which cannot be performed on 1D vectors. As a result, it is only applied to 2D weight matrices, while embeddings, biases, and other 1D parameters are updated with AdamW. ↩